
In this project I used a labeled dataset to create model for sentiment analysis of texts given to model.
The dataset contains the text of Donald Trump’s Tweet, the ex-president of united states.
Steps Of The Text Sentiment Analysis Project
There are 3 main steps in this project:
- Text Preprocess
- Word Embedding
- Training The Model
So, I will explain each step and also will show the code for each section, but if you want to check out the all of the code, I will leave the link of the notebook in Kaggle.
Dataset Link:
https://www.kaggle.com/datasets/albertsavill/all-trumps-twitter-insults-with-sentiment
Notebook Link:
https://www.kaggle.com/code/alishafaghi/trump-s-tweets-sentiment-analysis-using-lstm
Data Exploration
Before anything else, I splitted the data into test and train by ratio of 30% to 70%.
In the beginning I wanted to look at the data carefully so I used the Python Pandas library to check out the data.
First, I want to see only a few results from the top.
Code:
train= pd.read_csv("../input/trump-tweets/trump-train.csv",encoding='ISO-8859-1')
test= pd.read_csv('../input/trump-tweets/trump-test.csv')
test.head()So this is the result.
Oouput:
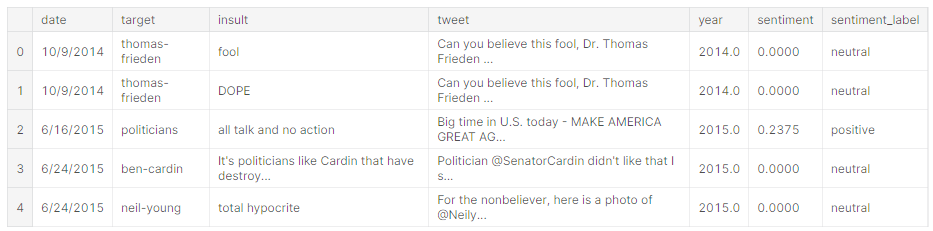
Next, I check out the info of data.
So here is the code and the results of what I checked.
Code:
Output:

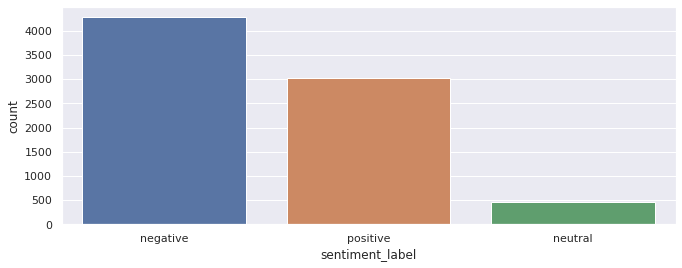
Next I wanted to see the count of tweets categorized in each sentiment label.
Code:
sns.set_style("whitegrid")
sns.set(rc={'figure.figsize':(11,4)})
sns.countplot(train['sentiment_label'])Output:
Text Preprocess
The next step is to preprocess the text and remove and clean it.
In this step I removed stop words, links, extra space and punctuations. Plus I corrected the miss spellings and tokenized the text.
Frist I used the NLTK library to identify the stop words, then I created a function using REGEX or regular expression to remove the things I just mentioned.
Code:
from nltk.corpus import stopwords
# load stop words
stop_word = stopwords.words('english')def clean(text):
# remove urls
text = re.sub(r'http\S+', " ", text)
# remove mentions
text = re.sub(r'@\w+',' ',text)
# remove hastags
text = re.sub(r'#\w+', ' ', text)
# remove digits
text = re.sub(r'\d+', ' ', text)
# remove html tags
text = re.sub('r<.*?>',' ', text)
# remove stop words
text = text.split()
text = " ".join([word for word in text if not word in stop_word])
return textThen I applied the function to test and train data separately
train['tweet'] = train['tweet'].apply(lambda x: clean(x))
test['tweet'] = test['tweet'].apply(lambda x: clean(x))Next, I used loc in Pandas to locate the columns I want for the test and train file to be equal to.
Code:
train = train.loc[:,['tweet','sentiment_label']]
test = test.loc[:,['tweet','sentiment_label']]Then I used label encoder to label each sentiment.
So, negative is equal to -1, neutral equal to 0 and positive is equal to 1.
label_encoder = preprocessing.LabelEncoder()
# Encode labels in column 'Sentiment'.
train['sentiment_label']= label_encoder.fit_transform(train['sentiment_label'])
train['sentiment_label'].unique()Output:
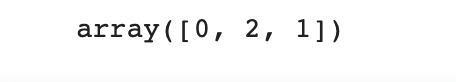
Alright so lets check again and see if the labels changed in dataset too.
Code:
train.head()Output:

Great, so it works and as you can see and the sentiment labels are numeric.
Next, I used train and test function to split the data into train and test by 70% to 30% respectively.
Code:
train_text,val_text,train_label,val_label=train_test_split (train.tweet, train.sentiment_label, test_size=0.3,random_state=42)
Then I used lemmatization to get the unique form of each words and after that I tokenized it.
Code:
class Lemmatizer(object):
def __init__(self):
self.lemmatizer = WordNetLemmatizer()
def __call__(self, sentence):
sentence=re.sub('(https?:\/\/)?([\da-z\.-]+)\.([a-z\.]{2,6})([\/\w \.-]*)',' ',sentence)
sentence=re.sub('[^0-9a-z]',' ',sentence)
return [self.lemmatizer.lemmatize(word) for word in sentence.split() if len(word)>1]tokenizer=CountVectorizer(max_features=5000,stop_words='english',lowercase=True,tokenizer=Lemmatizer())train_x=tokenizer.fit_transform(train_text).toarray()
tokenizer.get_params()Output:

Next , I managed the future names.
Code:
feature_names=tokenizer.get_feature_names()val_x=tokenizer.transform(val_text).toarray()test_x=test.tweet
test_label=label_encoder.transform(test['sentiment_label'])test_x_1=tokenizer.transform(test_x).toarray()Word Embedding
Next I started the word embedding process.
Code:
early_stop=EarlyStopping(monitor='val_accuracy',patience=3)
reduceLR=ReduceLROnPlateau(monitor='val_accuarcy',patience=2)token=Tokenizer(num_words=5000,oov_token=Lemmatizer())
token.fit_on_texts(train_text)
train_x_2=token.texts_to_sequences(train_text)
train_x_2=pad_sequences(train_x_2,maxlen=60,padding='post',truncating='post')val_x_2=token.texts_to_sequences(val_text)
val_x_2=pad_sequences(val_x_2,maxlen=60,padding='post',truncating='post')embedding_dimension=32
v=len(token.word_index)
model=Sequential()
model.add(Input(shape=(60,)))
model.add(Embedding(v+1,embedding_dimension))
model.add(LSTM(64,return_sequences=True))
model.add(GlobalMaxPool1D())
model.add(Dense(64))
model.add(Dense(3,activation='softmax'))Model Training
Finally I started to train the model.
Code:
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])
r=model.fit(train_x_2,train_label,validation_data=(val_x_2,val_label), epochs=50,batch_size=64,callbacks=[reduceLR,early_stop])Output:

Next, I plotted it
Code:
plt.plot(r.history['loss'])
plt.plot(r.history['val_loss'])
plt.title('LOSS',fontdict={'size':'22'})
plt.plot()Output:
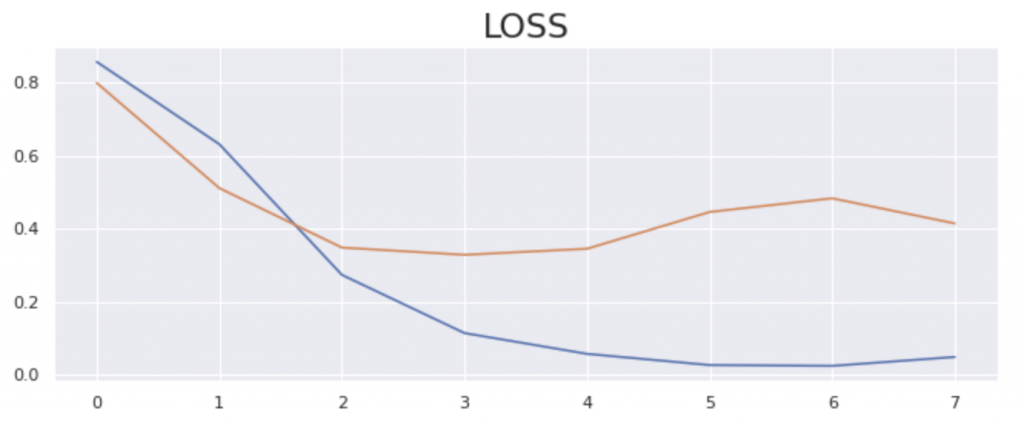






Output:
Code:
Output:
Code:
Output:
Code: